DataEng-Automated-Data-Pipeline-Project
An automated ETL data pipeline for immigration, temperature and demographics information
This project is maintained by HakbilenBerk
Udacity Data Engineering Capstone Project: Automated-Data-Pipeline
Project by Berk Hakbilen
Data pipeline for immigration,temperature and demographics information
Goal of the project
In this project the immigration information from the US is extracted from SAS files along with temperature and demographics information of the cities from csv files. The datasets are cleaned and rendered to JSON datasets on AWS S3. Later on JSON data is loaded on to staging tables on Redshift and then transformed to a star schema tables which also reside on Redshift. The whole pipeline is automated using Airflow.
Usecases
The database schema was constructed for following usecases:
- Get information regarding which cities and states were popular destinations for travelers/immigrants, the type of travel (sea/air etc.), age and gender information of travelers/immigrants.
- Obtain correlation between popular immigrations/travel destinations and the temperature and demographic information of the destination.
- Visa details such as visa type, visa expiration, travel purpose of the individuals.
Database Model

The data is stored on a Redshift cluster on AWS. The Redshift contains the staging tables which serve the purpose of hold the data from JSON files in S3 Bucket. Redshift cluster also contains a fact table called immigrations where immigration/travel information of individuals are listed. I used immigrations as the fact table where through the city attribute the queries can be extraploted to other dimension tables such as demographics, temperature and visa details to obtain further correlations between the immigration/travel information. I opted for the star schema to optimize the database for Online Analytical Processing (OLAP).
Database Dictionary
Please refer to “Airflow/data/I94_SAS_Labels_Descriptions.SAS” for abbreviations.
Immigration Fact Table
| Table Column | Data Type | Description |
|---|---|---|
| immigration_id (PRIMARY_KEY) | numeric | immigration id number |
| year | numeric | year of immigration |
| month | numeric | month of immigration |
| country_code | numeric | country of immigrant |
| city_code | varchar | arrival city |
| arrival_date | numeric | date of arrival |
| travel_mode | numeric | type of travel(sea, air…) |
| state | varchar | arrival state |
| age | numeric | age of immigrant |
| gender | varchar | gender of immigrant |
| flight_no | varchar | Flight number |
Visa Details Dimension Table
| Table Column | Data Type | Description |
|---|---|---|
| visa_id (PRIMARY_KEY) | numeric | visa id number - auto generated |
| travel_purpose | numeric | purpose of travel |
| admission_number | numeric | admission number |
| visa_type | varchar | type of the visa |
| visa_expiration | varchar | Expiry date of the visa |
Temperature Dimension Table
| Table Column | Data Type | Description |
|---|---|---|
| temp_id (PRIMARY_KEY) | varchar | temperature id number |
| date | date | date of measurement |
| ave_temp | numeric | average temperature that day |
| city | varchar | city of measurement |
| country | varchar | country of measurement |
| latitude | varchar | latitude of measurement |
| longitude | varchar | longitude of measurement |
Demographics Dimension Table
| Table Column | Data Type | Description |
|---|---|---|
| demo_id (PRIMARY_KEY) | varchar | demographics id |
| city | varchar | city |
| state | varchar | state |
| median_age | numeric | median of the age of population |
| male_population | numeric | male population |
| female_population | numeric | female population |
| total_population | numeric | total population |
| foreign_born | numeric | number of foreign-born residents |
| ave_household_size | numeric | the average number of household |
| state_code | varchar | code of the state the city is located in |
| race | varchar | name of a specific race |
| count | numeric | number of residents of that specific race |
Tools and Technologies used
The tools and technologies used:
- Apache Spark - Spark was used to read in the large data from SAS and CSV source files, clean them rewrite them in S3 bucket as JSON files.
- Amazon Redshift - The staging tables as well as fact and dimension tables are created on Redshift.
- Amazon S3 - S3 is used to store the large amounts of JSON data created.
- Apache Airflow - Airflow was used to automate the ETL pipeline.
Source Datasets
The datasets used and sources include:
- I94 Immigration Data: This data comes from the US National Tourism and Trade Office. A data dictionary is included in the workspace. here is where the data comes from.
- World Temperature Data: This dataset came from Kaggle. You can read more about it here.
- U.S. City Demographic Data: This dataset came from Kaggle. You can read more about it here.
- Airport Code Table:This is a simple table of airport codes and corresponding cities. It comes from here
Airflow: DAG Representation
Main DAG

The convert_to_json.py file used to convert the source data to JSON data on S3 bucket is thought of as a one time run process to convert the data. Therefore, it is not implemented in the DAG as a task.
Installation
Firstly, clone this repo.
Create a virtual environment called venv and activate it
$ python -m venv venv
$ source venv/Scripts/activate
- If you are using linux to run Airflow, make sure to install all required python packages:
$ pip install -r requirements.txt - If you are using Windows, you need to launch Airflow using Docker. The required Docker configuration is included in the repo:
$ docker-compose up
You can access Airflow UI on your browser by going to:
http://localhost:8080/
Use user= user and password= password to login to Airflow.
Workflow
-
Fill in your AWS access and secret keys in the aws.cfg file under Airflow/ directory.
-
Create an S3 Bucket on AWS and fill in the S3_Bucket in aws.cfg with your bucket address (s3a://your_bucket_name)
-
Create a new folder called “data_sas” under airflow/data. Download the SAS data files from here and copy them in the folder you just created. Also download “GlobalLandTemperaturesByCity.csv” from here and copy it under airflow/data along with other csv files (Because these data files are too large, they are not included in this repo. Therefore you need to download them manually).
- Change to airflow/tools directory and run the convert_to_json.py. This will read in the source files into Spark, transform them to JSON and write to the given S3 bucket.
python convert_to_json.py -
Go to “http://localhost:8080/” in your browser. Click on the Admin tab and select Connections.
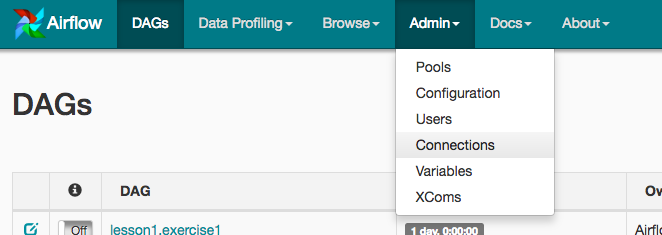
-
Under Connections, select Create.
- On the create connection page, enter the following values:
- Conn Id: Enter aws_credentials.
- Conn Type: Enter Amazon Web Services.
- Login: Enter your Access key ID from the IAM User credentials.
- Password: Enter your Secret access key from the IAM User credentials.
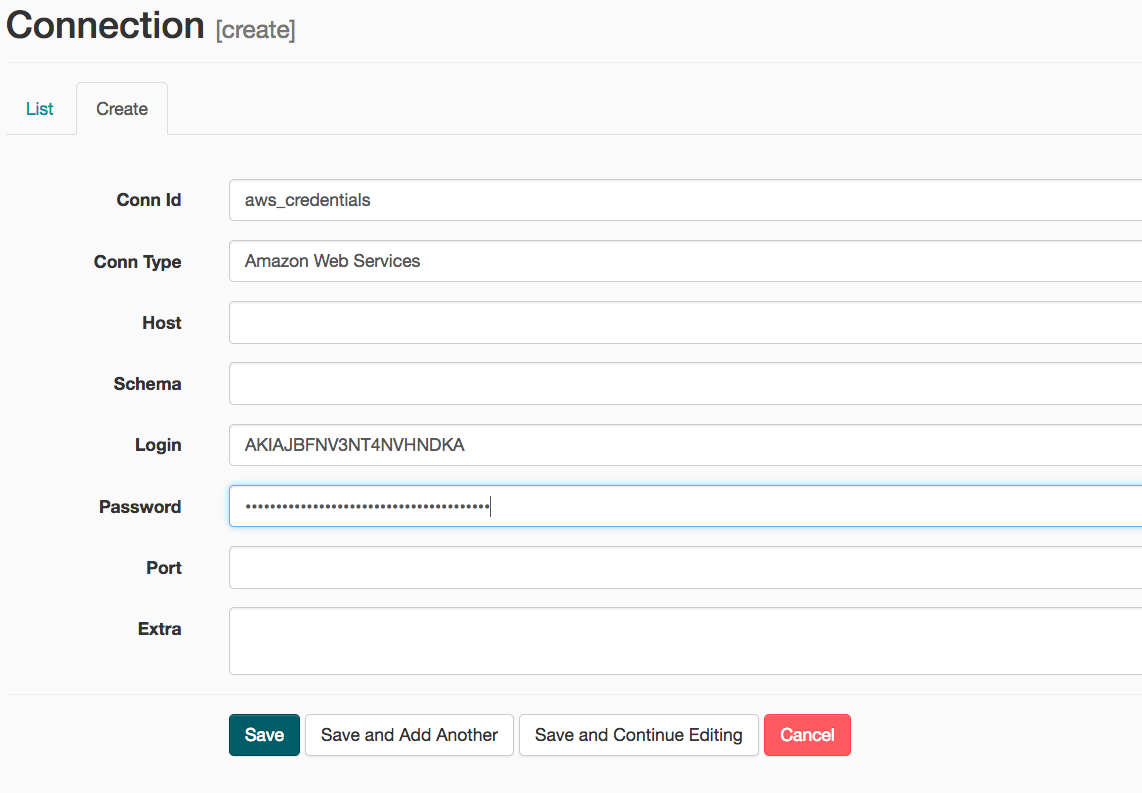 Once you’ve entered these values, select Save and Add Another.
Once you’ve entered these values, select Save and Add Another.
- Create a Redshift cluster on AWS. On the next create connection page, enter the following values:
- Conn Id: Enter redshift.
- Conn Type: Enter Postgres.
- Host: Enter the endpoint of your Redshift cluster without the port at the end.
- Schema: Enter the Redshift database you want to connect to.
- Password: Enter the password you created when launching your Redshift cluster.
- Port: Enter 5439.
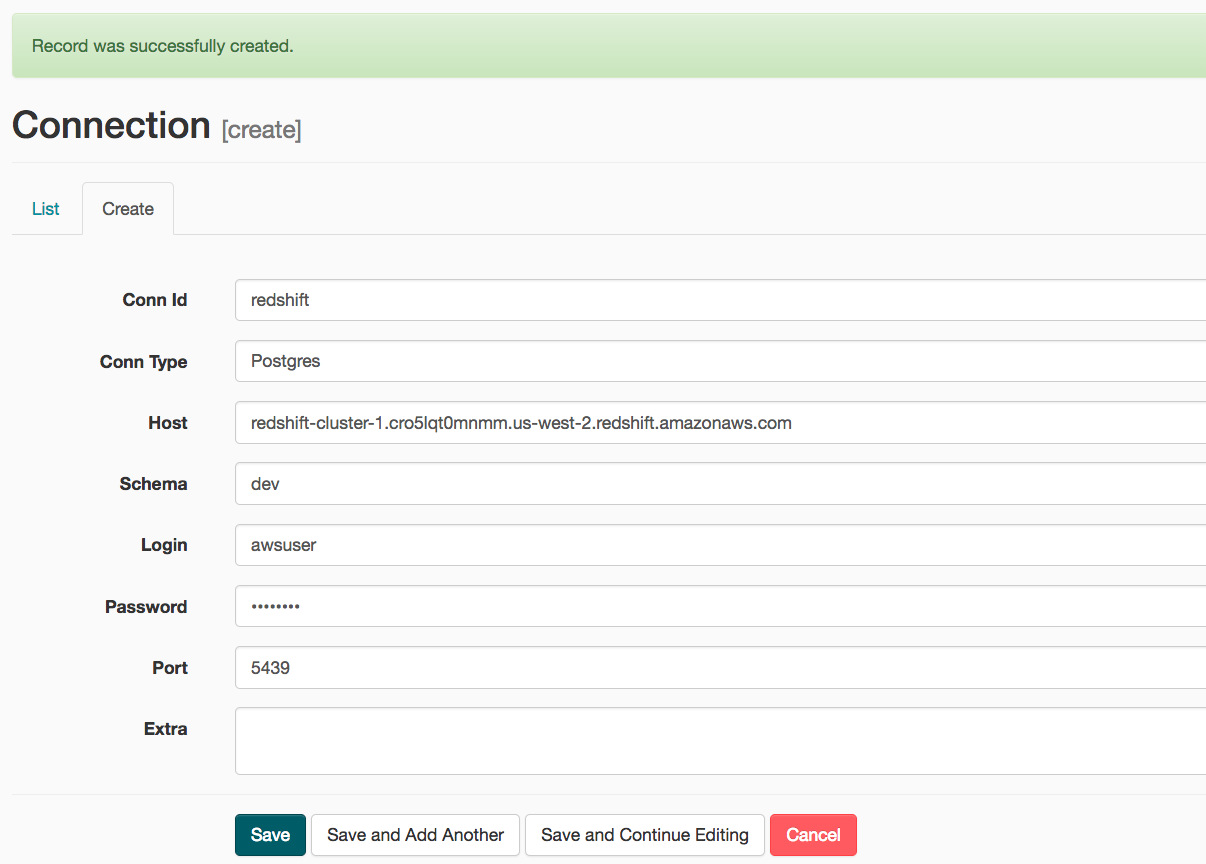 Once you’ve entered these values, select Save.
Once you’ve entered these values, select Save.
- Run main_dag under DAGS by toggling its switch from off to on.
How to handle possible scenarios
- The data was increased by 100x.
- Because the data is already large Spark was our choice to read in and process the data. However if the data increases even more, Deploying spark on an EMR cluster would be a good solution.
- If the pipelines were needed to be run on a daily basis by 7am:
- Dags can be set to run according to a schedule. So the main_dag in Airflow can be set to run everyday at 7am.
- If the database needed to be accessed by 100+ people:
- Distribute the fact table and one dimension table on their common columns using DISTKEY.
- Using elastic resize.